Automatic Donald Trump
Donald Trump's smart keyboard
I always wanted to implement a Markov chain. They are used all over: in compression, speech recognition, telco error correction, Bayesian inference, economics, genetics, biology. They run your smartphone's writing suggestions. Hell, even Google's PageRank (the thing that kind of pays my bills) is defined using a Markov chain.
Markov's idea is actually pretty simple — but its simplicity is often obstructed by thick layers of mathematical formulas and formal definitions. Few people actually grok it.
This is my shot at explaining Markov chains in a palatable and maybe even enjoyable way. How do I want to make this article enjoyable? Two things:
- Actual code.
- Donald Trump.
Since people encounter Markov chains most often when writing text on a mobile device (it's the auto-suggestions of next words when you're typing), I'll drop most of the generality of Markov's original idea and I'll focus solely on text here. (Specifically, Donald Trump's tweets.) We can always generalize later on.
To be clear, if you understand markov chains or even implemented one, this article is of no use to you. You can invest the saved time in procrastinating with the virtual Donald Trump above.
Note: Since I started hacking on this last weekend I have learned about others with very similar ideas. There's a twitter bot called Bob Markov that posts Trump-esque tweets every 15 minutes. There's a Donald Trump chatbot. There's a Trump speech generator. Seems like Trump has at least one positive impact: he reminds people of a Markov chain, and some of those people then go ahead and implement one, learning something in the process. #ThanksTrump!
Intuition about Markov chains
Let's have a look at the following source text:
tick tock tick tock tick tock tick tock
(Disclaimer: this is not a Donald Trump tweet.)
We can say the following:
- When the current word is "tick", the next word will be "tock" 100% of the time.
- When the current word is "tock", the next word will be "tick" 75% of the time, and it will be a newline the rest (25%) of the time.
That's it! We have now defined a Markov chain.
From this definition of probabilities, we can now help users with writing similar text, or we can generate completely new texts autonomously.
- Let's start with "tock".
- The generator knows the probabilities of the possible next words after "tock": 75% "tick", 25% newline.
- If we are writing an auto-suggesting keyboard, we can now place "tick" prominently and something like "enter" less prominently.
- If we're building a text generator, we pick the next word randomly. Either completely randomly (50% tick, 50% newline) or in proportion (tick has 3 times the chance than newline). We're using the second approach here, as it generates text that is closer to the original.
- Let's say we ended up with "tick". The generated string is now "tock tick".
- Next, we take the last word ("tick") and repeat for that word.
- The probabilities for "tick" are simple (100% "tock"). If we are writing an auto-suggestion keyboard, we can even insert "tock" without asking the user (if that's the kind of domain we're in).
- We now have "tock tick tock".
- Repeat.
Order
Markov chains have very short memory. That's actually an important property of theirs: the so called Markov property. In the example above, the next word only depends on the current word, and nothing else. The words before that are irrelevant — the system has no memory of them.
With the tick tock example, that's all you really need. For other types of texts, though, you might want the system to remember more than one word.
In that case, we say that the Markov chain is of order m. As far as I know, smart keyboards mostly use Markov chains of order 2, meaning that the next word is suggested based on the current word and the one word before it.
You can of course go with higher orders, but the internal representation of the chain then grows exponentially, and you also start to basically copy the source texts word for word (unless you have a very very large source text).
Donald J. Trump-o-mat
Ok, now for the fun part.
See, "tick tock..." is not the only possible source text. Smart keyboards use probabilities derived from huge corpora of real-life text. (They also modify the probabilities according to what you type, so that the keyboard adapts to you.)
I don't have a huge corpus of English text but I do have access to something much weirder and funnier: Donald Trump's twitter account.
The fun part about Markov chains is that despite their simplicity and short memory, they can still generate believable texts (or other simulations). The web app I made is merely a 2nd order Markov chain generated from about 11 thousand of Donald Trump's tweets. Unless by chance, none of the tweets this web app generates are actual tweets made by Donald Trump. But every set of 3 words (tokens, actually) that you see in these generated tweets have been at least once uttered by @realDonaldTrump.
Implementation details
I've made a tiny Dart package for Markov chains. Here it is in action:
// Take POSIX standard input stream (or any other byte
// stream) and use it as source text.
var chain = await stdin
.transform(new Utf8Decoder())
.transform(new LineSplitter())
.pipe(new MarkovChainGenerator(2));
(Not sure what Dart is? Click here. The syntax should feel familiar, though.)
The two transform() calls are there to convert the byte stream to a stream of (unicode) lines. Then this stream is piped to a Markov chain generator of order 2. This returns a Future of a MarkovChain instance, which we happily await (if you're not familiar with async/await, this means the following code is basically a callback that is executed only after the Markov chain generator is finished).
Now, we can generate new text from the chain like so:
// Generate 20 words.
var tokens = chain.generate().take(20).toList();
// Format them and print them.
print(format(tokens));
The format() function takes the tokens (such as great, again or !) and use their metadata to string them together so that you get valid English syntax (great again! instead of great again !).
Internally, the Markov chain is a simple object with some methods and one large HashMap that's defined like so:
Map<TokenSequence, ProbabilityDistribution<String>> _edges;
You can read the type definition with generics like this: "the object Maps from TokenSequences to ProbabilityDistributions of Strings". That's actually very close to what it does. It keeps track of probability distributions of the next strings (words) after each sequence of tokens.
See, Markov chains can also be seen as directed graphs with edges between different states. The edges can carry different weight (like with the 75% and 25% in the example above).
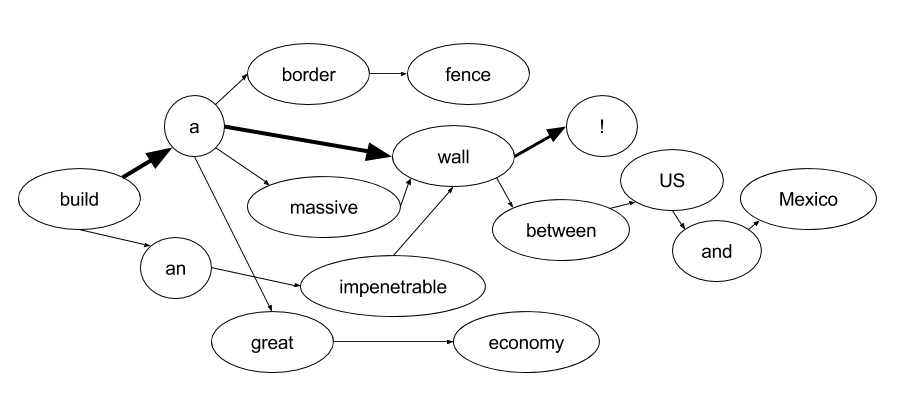
For us, the current state is a sequence of tokens (words or punctuation) because we need to accommodate for Markov chains of orders higher than 1. So the TokenSequence holds the last m number of words uttered (where m is the order of the Markov chain). Since we're using a Hash Map to go from current state to the next token, we need to make sure that sequences of tokens have meaningful hashCodes (unique and based on all of the tokens). Here's the code in question:
class TokenSequence {
final Queue<Token> _tokens;
// ...
@override
int get hashCode =>
hashObjects(_tokens.map((token) => token.string));
}
Normally, each new Dart object gets a unique hash. Here we're overriding this behavior and saying that sequences with the same tokens (as defined by the tokens' string representations) should be considered same.
The hashObjects function is taken from the Google-maintained quiver package. (It's similar to guava in many respects.) This function takes an iterable of objects, their hashes, and creates a combined hash using Jenkins hash function.
Let's say the starting sequence is {"I", "am"} (Markov chain of order 2, so two tokens). Statistics tell us that when Donald Trump says "I am" on Twitter, he likely continues with "self" (so he can say "I am self-funding ...") or "the" (so he can say "I am the only candidate that ...").
This information is stored in the HashMap above so that internally, here's how we find a random next state:
var distribution = _edges[state];
var nextWord = distribution.pick(_random);
The first line just looks up the ProbabilityDistribution associated with the current state.
The distribution.pick() method does a "wheel of fortune" thing (picks a token randomly, keeping the probabilities observed in the source text). We inject _random (defined elsewhere) in case we'd like to use a seeded random generator (better for testing). Here is the ProbabilityDistribution class in its entirety (explained below):
class ProbabilityDistribution<T> {
final Map<T, int> _records = new Map();
int total = 0;
T pick(Random random) {
int randomNumber = random.nextInt(total);
int currentIndex = 0;
for (T key in _records.keys) {
int currentCount = _records[key];
if (randomNumber < currentIndex + currentCount) {
return key;
}
currentIndex += currentCount;
}
}
void record(T word, {int count: 1}) {
_records.putIfAbsent(word, () => 0);
_records[word] += count;
total += count;
}
}
The class uses generics so that we can later easily change from String to anything else.
The record() function takes a word, adds it to the internal Map if neccessary, and updates its count and the total count. So, when done, we have something like this:
- Probability distribution for
{"I", "am"}:"self"- 6"the"- 4- total - 10
The pick() function first generates a random integer from zero to total. This is where the "needle" stops on the circumference of the imaginary wheel of fortune. Next, we go key by key, claiming the proportional part of the wheel's circumference, and seeing if the random number is inside that range.
Once we have the next word, we can go to the next iteration.
state = new TokenSequence.fromPrevious(state, nextToken);
What this does is that it takes the current sequence of tokens, like {"I", "am"}, the next token, like the, and creates the following state, which in this example would be {"am", "the"}. This sequence can then serve as a basis for another probability distribution, and another token, and another state.
Tokenization
One implementation detail that I had to solve quickly (but satisfactorily) was tokenization of tweets (splitting the string into meaningful words and punctuation). The first implementation was as simple as line.split(" ") and it worked quite well. But it was, as Mr Trump would say, "Stupid!" Here's the current implementation:
Iterable<String> _tokenizeLine(String line) sync* {
var scanner = new StringScanner(line.trim());
while (!scanner.isDone) {
if (scanner.scan(_link) ||
scanner.scan(_twitterMention) ||
scanner.scan(_numberOrTime) ||
scanner.scan(_word) ||
scanner.scan(_punctuation)) {
yield scanner.lastMatch[0];
}
// Skip whitespace if any.
scanner.scan(_whiteSpace);
}
// Add a newline at the end.
yield "\n";
}
This uses the string_scanner package (also maintained by Google) and also the sync generator language feature (yield) which I got used to in Python and I use it in Dart even more.
We're scanning for specific strings like links and mentions first, so that for example .@BarackObama isn't tokenized as {".", "@BarackObama"} (we want it together).
Discounting that, it's as simple as scanning for words or punctuation, and ignoring possible whitespace in between, until we've scanned each line.
Building the Markov chain in the browser
Another implementation 'detail' is performance in the browser. What we're doing is downloading a ~1MB text file, splitting it into lines, and feeding it — one line at a time — to the Markov chain generator, which then processes it. That's a lot of work for a web app.
We could do this in a separate isolate (and, therefore, thread) but that would be quite a bit of additional work. This is a weekend project, not a business.
A much simpler approach is to make sure we never block the UI thread for too long. Here's how:
Stream<String> _splitToLines(String file) async* {
StringScanner scanner = new StringScanner(file);
int lineCount = 0;
while (!scanner.isDone) {
if (scanner.scan(_line)) {
yield scanner.lastMatch[0];
}
// Scan and discard any newlines.
scanner.scan("\n");
lineCount += 1;
if (lineCount % maxLinesPerFrame == 0) {
// Give the UI thread a break.
await window.animationFrame;
}
}
}
Each maxLinesPerFrame (defined elsewhere), we wait for the next animation frame. It would be a huge pain without async/await. But with it, it's super simple to await the next window.animationFrame every few iterations.
Conclusion
I think choosing Donald Trump's tweets as the source text was a great decision. Not only is it opportune (for readers from the distant future: this code and article is being written at a time in which it's unsure whether or not Donald Trump — yes, that Donald Trump – will be or won't be the president of the United States) but more importantly, Mr. Trump's utterances are so idiosyncratic that, for many of the auto-generated tweets, you could probably tell they were supposed to be written by Donald Trump even if I didn't provide the visual hints.
Also, his tweets are a little retarded incoherent by themselves, so the additional retardation incoherency (which stems solely from the short memory of the algorithm) fits quite well.
To be clear, though, the library can work with any input material. I was initially planning to also include automatic Jesus (quotes from Bible) and/or automatic Hillary Clinton. The possibility to upload your own arbitrary text would also be awesome and shouldn't be too hard. Hopefully, I'll have the time to do this during March or April. In the meantime, you can always use the command line version of the generator that comes with the Dart package.